- 프로그램이 실행될 때 당장 수행해야 할 부분만 메모리에 올려놓고 그렇지 않은 부분은 디스크의 스왑 영역에 내려놓았다가 필요해지면 교체하는 방식 사용
- 가상메모리 : 프로세스마다 각각 0번지부터 가지는 주소공간 (일부는 물리적 메모리, 일부는 디스크의 스왑 영역)
- 프로세스의 주소 공간을 메모리로 적재하는 단위에 따라
- 요구 페이징 방식 : 대부분 사용
- 요구 세그먼테이션 방식 : 페이지드 세그먼테이션 기법을 사용하는 경우
요구 페이징
- 요구 페이징 : 프로그램 실행 시 프로세스를 구성하는 모든 페이지를 한꺼번에 메모리에 올리는 것이 아니라 당장 사용될 페이지만 올리는 방식
- ✅ 당장 필요한 부분만 올리기 때문에 메모리 사용량 감소
- ✅ 프로세스 전체를 메모리에 올리는 데 소요되는 입출력 오버헤드 감소
- ✅ 응답시간 단축, 더 많은 프로세스 수용 가능
- ✅ 프로그램이 물리적 메모리의 용량 제약을 벗어날 수 있도록 함 (메모리 용량보다 큰 프로그램도 실행가능)
- 유효-무효 비트 : 어떤 페이지가 메모리에 존재하는지 구별하기 위한 방법
- 유효 : 특정 페이지가 참조되어 메모리에 적재되는 경우
- 무효 : 적재되어 있던 페이지가 디스크의 스왑 영역으로 쫓겨날 경우
- page fault : CPU가 참조하려는 페이지가 현재 메모리에 올라와 있지 않아 무효비트로 세팅되어 있는 경우
1. 요구 페이징의 페이지 부재(page fault) 처리
- CPU가 무효 페이지에 접근하면 MMU (주소 변환 하드웨어)가 page fault trap을 발생시킴
- CPU의 제어권이 커널모드로 전환되고 OS의 page fault handler가 호출됨
- 해당 페이지를 메모리에 적재하기 전에 해당 페이지에 대한 접근이 적법한지 체크
- 적법한 경우, 물리적 메모리에서 비어 있는 프레임을 할당받아 해당 페이지를 읽어옴 (비어있는 프레임이 없다면 기존에 메모리에 올라와 있는 페이지 중 하나를 스왑아웃)
적법하지 않은 경우, 해당 프로세스 종료
2. 요구 페이징의 성능
- 성능에 가장 큰 영향을 미치는 요소 =
page fault 발생 빈도 - page fault 발생 빈도 ⬇ 유효 접근시간 ⬇ 요구 페이징의 성능 ⬆

페이지 교체
- 페이지 교체 : page fault가 발생해서 요청된 페이지를 메모리로 읽어와야 하는데, 물리적 메모리에 빈 프레임이 없어 메모리에 올라와 있는 페이지 중 하나를 스왑아웃시키는 것
- 페이지 교체 알고리즘 : 페이지 교체 시 어떤 페이지를 쫓아낼 것인지 결정하는 알고리즘
- 목표 : 페이지 부재율 최소화 ⇒ 가까운 미래에 참조될 가능성이 가장 적은 페이지를 내쫓아야 함
1. 최적 페이지 교체 (Optimal Algorithm: MIN, OPT
- 물리적 메모리에 존재하는 페이지 중 가장 먼 미래에 참조될 페이지를 쫓아내는 방식
페이지 참조열 : 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5, 프레임 4개
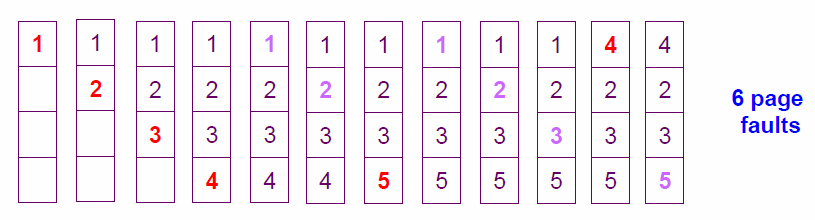
- 초기에 메모리가 비어 있기 때문에 4회까지는 page fault 불가피하게 발생 ⇒
4 - 페이지 5를 참조하려 할 때 page fault 발생 ⇒
1
이 때, 가장 먼 미래에 참조될 페이지 선정 (여기서는 4번이 가장 먼 미래에 참조되므로 4번 스왑아웃) - 페이지 4를 참조하려 할 때 다시 page fault 발생 ⇒
1
⇒ 총6회의 page fault 발생 - ❌ 미래에 어떤 페이지가 어떤 순서로 참조될지 미리 알고 있다는 전제하에 운영하므로 실제 사용할 수 없음
오프라인 알고리즘 - ✅ 페이지 교체 알고리즘 중 가장 적은 페이지 부재율을 보장 ⇒ 다른 알고리즘의 성능에 대한 상한선 제공
2. 선입선출 알고리즘 (First In First Out: FIFO)
- 물리적 메모리에 가장 먼저 올라온 페이지를 우선적으로 내쫓는 방식
- ❌ 페이지의 향후 참조 가능성을 고려하지 않고, 들어온 순서대로 내쫓기 때문에 비효율적인 상황 발생 가능
페이지 참조열 : 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5, 프레임 3, 4개
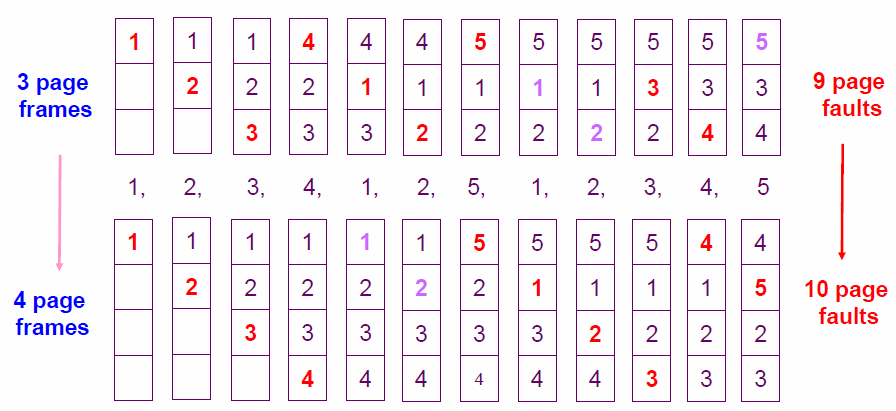
- 메모리 프레임이 3개인 경우, page fault 9번 발생
- 메모리 프레임이 4개인 경우, page fault 10번 발생
⇒ 물리적 메모리 공간이 늘어났음에도 오히려 성능은 더 나빠짐FIFO 이상현상
3. LRU 알고리즘 (Least Recently Used)
- 시간지역성 (temporal locality) : 최근에 참조된 페이지가 가까운 미래에 다시 참조될 가능성이 높은 성질
- 시간지역성을 이용해 가장 오래전에 참조가 이루어진 페이지를 쫓아내는 방식
페이지 참조열 : 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5, 프레임 4개
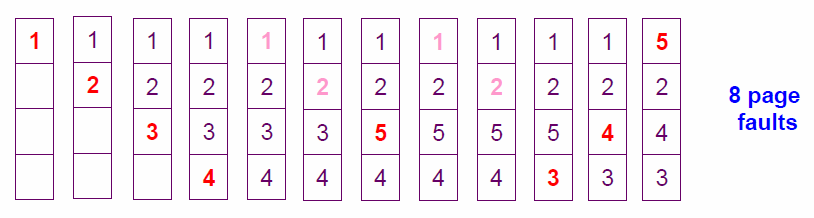
- 초기에 메모리가 비어 있기 때문에 4회까지는 page fault 불가피하게 발생 ⇒
4 - 페이지 5를 참조하려 할 때 page fault 발생 ⇒
1
이 때, 가장 오래전에 참조된 페이지 쫓아냄 (여기서는 3번이 가장 오래전에 참조되었으므로 3번 스왑아웃) - 이후, 페이지 3, 4, 5를 참조하려 할 때 각각 page fault 발생 ⇒
3
⇒ 총8회의 page fault 발생
4. LFU 알고리즘 (Least Frequently Used)
- 과거 참조횟수가 가장 적었던 페이지를 쫓아내는 방식 (여러 개인 경우, 임의로 하나 선정)
- 페이지 참조횟수를 계산하는 방식에 따라
- Incache-LFU : 페이지가 물리적 메모리에 올라온 후부터의 참조 횟수 카운트, 쫓겨났다가 돌아온 경우 리셋
- Perfect-LFU : 메모리 적재여부와 상관없이 그 페이지의 과거 총 참조 횟수 카운트
- ✅ 페이지의 참조횟수를 정확히 반영할 수 있음
- ❌ 메모리에서 쫓겨난 페이지의 참조 기록까지 모두 보관해야 하므로 오버헤드가 큼
- ✅ LRU 보다 성능 향상에 있어서는 더 효율적
- ✅ 직전에 참조된 시점만을 반영하는 LRU와 달리 오랜 시간동안의 참조 기록을 반영한다는 장점
- ❌ 시간에 따른 페이지 참조의 변화를 반영하지 못하고, 구현이 복잡함
페이지 참조열 : 1, 1, 1, 1, 2, 2, 3, 3, 2, 4, 5, 프레임 4개

- LRU : 가장 오래전에 참조된 1번 페이지를 삭제
- LFU : 가장 적게 참조된 4번 페이지를 삭제
5. Clock 알고리즘 (NUR, NRU)
- LRU와 LFU는 페이지의 참조 시각, 참조 횟수를 소프트웨어적으로 유지하고 비교해야 하므로 시간적 오버헤드 발생
- Clock 알고리즘 : 하드웨어적인 지원을 통해 알고리즘의 운영 오버헤드를 줄인 방식
- LRU vs Clock 알고리즘
- LRU : 가장 오래전에 참조된 페이지를 교체
- Clock 알고리즘 : 오랫동안 참조되지 않은 페이지 중 하나를 교체, 즉 가장 오래되었다는 것을 보장하지는 못함, LRU를 근사시킨 알고리즘
- ✅ 하드웨어적인 지원으로 동작하므로 LRU에 비해 페이지의 관리가 훨씬 빠르고 효율적
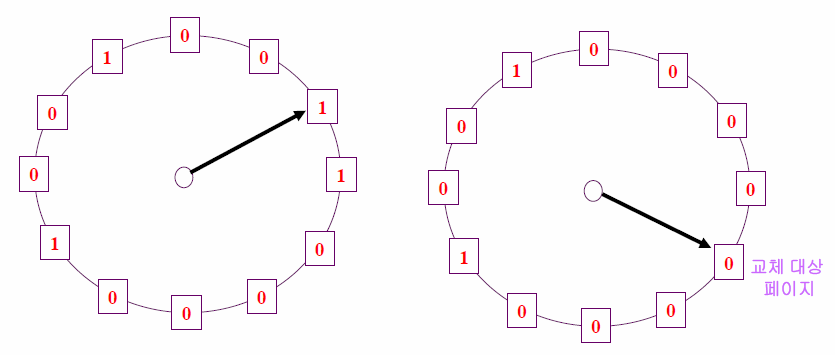
- 과정
- 교체할 페이지 선정을 위해 페이지 프레임들의
참조비트를 순차적으로 조사
참조비트: 각 프레임바다 하나씩 존재, 프레임 내의 페이지가 참조될 때 하드웨어에 의해 1로 자동 세팅 - 참조비트가 1인 페이지는 0으로 바꾸고 지나가고 참조비트가 0인 페이지는 교체
시곗바늘이 한 바퀴 돌아오는 동안에도 여전히 0이라면 다시 참조되지 않았다는 뜻이므로 그만큼 자주 사용하지 않았다고 간주 - 모든 페이지 프레임을 다 조사한 경우, 첫 번째 프레임부터 조사 반복
- 교체할 페이지 선정을 위해 페이지 프레임들의
⇒ 적어도 시곗바늘이 한 바퀴 도는 데 소요되는 시간만큼 페이지를 메모리에 유지시켜둠으로써 페이지 부재율을 줄임 2차 기회 알고리즘
페이지 프레임의 할당
- 프로세스 여러 개가 동시에 수행되는 상황에서 각 프로세스에게 할당할 메모리 공간을 효율적으로 할당해야 함
- 균등할당 방식 (Equal allocation) : 모든 프로세스에게 페이지 프레임을 균일하게 할당
- 비례할당 방식 (Proportional allocation) : 프로세스의 크기에 비례해 페이지 프레임을 할당
- 우선순위 할당방식 (Priority allocation) : 우선순위에 따라 페이지 프레임을 다르게 할당
- 당장 CPU에서 실행될 프로세스에게 더 많은 페이지 프레임 할당
전역교체와 지역교체
- 교체할 페이지를 정할 때, 교체 대상이 될 프레임의 범위를 정하는 방법
- 전역교체 (Global replacement) : 모든 페이지 프레임이 교체 대상이 될 수 있는 방법
- 프로세스마다 메모리를 할당하는 것이 아니라 전체 메모리를 각 프로세스가 공유해서 사용하고 교체 알고리즘에 근거해서 할당되는 메모리 양이 가변적으로 변하는 방법
- 즉, 페이지 교체 시 다른 프로세스에게 할당된 프레임을 빼앗아올 수 있는 방법
- ✅ 프로세스별 프레임 할당량을 조절할 수 있음
- 지역교체 (Local replacement) : 현재 수행중인 프로세스에게 할당된 프레임 내에서만 교체 대상을 선정할 수 있는 방법
- 프로세스마다 페이지 프레임을 미리 할당하는 것을 전제로 함
스레싱
- 프로세스가 최소한의 페이지 프레임을 할당받지 못할 경우, 성능상의 심각한 문제 발생가능
- 스레싱 : 집중적으로 참조되는 페이지들의 집합을 메모리에 한꺼번에 적재하지 못해 페이지 부재율 ⬆ CPU 이용률 ⬇ 되는 현상
- 스레싱이 발생하는 과정
- 운영체제는 CPU 이용률이 낮을 경우, 메모리에 올라와 있는 프로세스 수가 적기 때문이라고 판단 ⇒ MPD (Multiprogramming Degree, 메모리에 동시에 올라가는 프로세스의 수)를 높이게 됨
- 하지만 MPD ⬆, 각 프로세스에게 할당되는 메모리의 양 ⬇
- 프로세스가 원활하게 수행되기 위해 필요한 최소한의 프레임도 할당받지 못하는 상태가 되면 page fault 발생 ⬆, CPU 이용률 ⬇
- 운영체제는 이를 또 메모리에 올라와 있는 프로세스 수가 적기 때문이라고 판단하고 MPD를 높이기 위해 또 다른 프로세스를 메모리에 추가
- 프로세스당 할당된 프레임의 수 더욱 ⬇, page fault 발생 더욱 ⬆
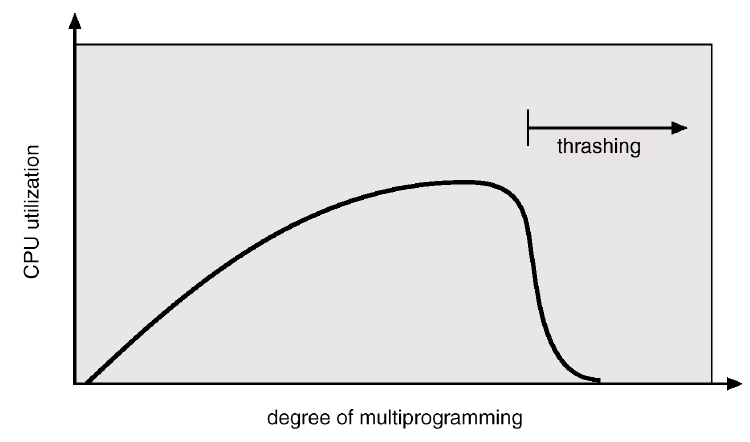
⇒ MPD와 CPU 이용률의 상관관계 (MPD가 증가하면 CPU 이용률도 비례해서 증가하지만, 어느 한계치를 넘어서면 급격히 떨어짐 ⇒ 스레싱)
⇒ 스레싱이 발생하지 않도록 하면서 CPU 이용률을 최대한 높일 수 있도록 MPD를 조절하는 것이 중요!
1. 워킹셋 알고리즘 (working-set algorithm)
- 지역성 집합 (locality set) : 프로세스가 일정시간 동안 집중적을 참조하는 페이지들의 집합
- 워킹셋 알고리즘 : 지역성 집합이 메모리에 동시에 올라갈 수 있도록 보장하는 메모리 관리 알고리즘
- 워킹셋 : 프로세스가 일정시간 동안 원활히 수행되기 위해 한꺼번에 메모리에 올라와 있어야 하는 페이지들의 집합
- 워킹셋을 구성하는 페이지들이 한꺼번에 메모리에 올라갈 수 있는 경우만 메모리 할당
- 그렇지 않을 경우, 할당된 페이지 프레임 모두 반납시킨 후 해당 프로세스 주소 공간 전체를 디스크로 스왑아웃
- 메모리에 올라와 있는 프로세스들의 워킹셋 크기의 합이 프레임의 수보다 클 경우, 일부 프로세스를 스왑 아웃시켜서 남은 프로세스의 워킹셋이 메모리에 모두 올라가는 것 보장 ⇒ MPD 줄이는 효과
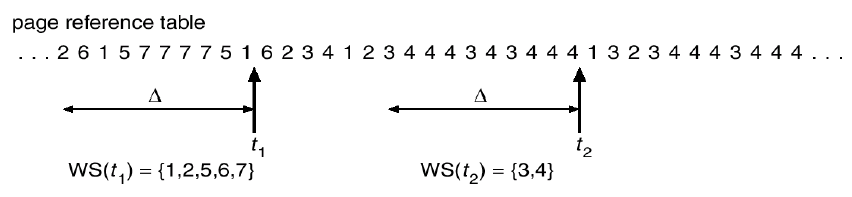
- 워킹셋 윈도우
- 크기 ⬇ : 지역성 집합을 모두 수용하지 못할 수 있음
- 크기 ⬆ : 여러 규모의 지역성 집합을 수용할 수 있지만, MPD가 감소해 CPU 이용률이 낮아질 수 있음
- 프로세스들의 지역성 집합을 효과적으로 탐지할 수 있는 윈도우 크기 결정하는 것이 중요!
- ✅ 동적 프레임 할당 기능까지 수행 (프로세스가 메모리를 많이 필요로 할 때는 많이 할당하고 적게 필요로 할 때는 적게 할당)
2. 페이지 부재 빈도 알고리즘 (page-fault frequency scheme: PFF)
- 프로세스의 페이지 부재율을 주기적으로 조사 후, 이 값에 근거해 각 프로세스에 할당할 메모리 양을 동적으로 조절
- 프로세스의 페이지 부재율이 상한값을 넘게 되면, 이 프로세스에 할당된 프레임 수가 부족하다고 판단하여 추가로 더 할당 ⇒ 빈 프레임이 없다면 일부 프로세스를 스왑 아웃시켜 메모리에 올라가 있는 프로세스 수 조절
- 프로세스의 페이지 부재율이 하한값 이하로 떨어지면, 이 프로세스에 필요 이상으로 많은 프레임이 할당된 것으로 간주해 할당된 프레임 수 줄임 ⇒ 메모리 내에 존재하는 모든 프로세스에 다 할당한 후에도 프레임이 남는 경우 스왑아웃 되었던 프로세스에게 프레임을 할당함으로써 MPD 높임